What is XPath?
XPath stands for XML Path. It is used for navigation of XML documents and allows selecting individual elements, attributes, or other part of an XML document for specific processing. An XMP path consists of one or more location steps, each separated by a forward slash (/).
When you need to search for an element, you need the starting point to start locating an element. In XPath this starting point is called the context node. The topmost element of the tree is called the root element.
Types of XPath
There are two types of XPath:
1. Native XPath (Also known as Absolute XPath)
This is an approach to locate element using XPath in a direct way by navigating through the complete path.
Example:
html/head/body/table/tr/td
html/body/div[1]/div/div/div[2]/form/span[2]/div/div/div[1]/div[4]/div/div[2]/div/span[1]
Absolute/Native XPath starts with the root node or a forward slash (/).
Finding an element by specifying native XPath is easy and fast as we are mentioning the direct path but this provides a fragile locator. If there is any change in the path resulting from changes in the code then such XPath will easily break.
2. Relative XPath
In Relative path, position of an element can be determined by specifying known attributes of the element itself or through the known attributes of nearby element. In this case there will be less chances of broken script as a result of html changes until or unless that particular path has changed.
Example:
//*[@name=’loginForm’]/input[1]
//div[@id=’product_tablist_two’]/span
In relative XPath, the path starts from the node of your choice – that is usually a known node present close to your target node. It starts with Double forward slash (//)
Locating element using relative path is less fragile but it will take more time in processing the element as we are specifying the partial path not the exact path.
If there are multiple elements found for given path, it will select the first identified element.
Important: If the attributes are not available for your target element, use any other element on the page that does have static attributes and also have the parent/child/sibling relationship with target element. A good way to start with XPath locator is to start with an element that you know is not likely to change much and use it as an ‘anchor’ in your locator. Your anchoring element can be above or below your target element in the HTML tree.
Symbols used in XPath expressions
Some important symbols that are used while describing XPath expression are given below:
| Symbol | Description |
| / | Selects immediate children of the left-side collection. An expression prefixed with a forward slash (/) uses the root of the document tree as the context.
Example: /employee – Selects the root element <employee> author/first-name – All <first-name> elements within an <author> element of the current context node. |
| // | Recursive descent; searches for the specified element at any depth. An expression that uses the double forward slash (//) indicates a search that can include zero or more levels of hierarchy. When this operator appears at the beginning of the pattern, the context is relative to the root of the document.
This is an abbreviation for /descendant-or-self::node() Example: .// Indicates that the context starts at the level in the hierarchy indicated by the current context. //employee Selects all employee elements no matter where they are in the document bookstore//title All <title> elements one or more levels deep in the <bookstore> element (arbitrary descendants). //@lang Selects all attributes that are named lang bookstore//book/excerpt//emph All <emph> elements anywhere inside <excerpt> children of <book> elements, anywhere inside the <bookstore>element: |
| . | Indicates the current node. This is an abbreviation for self::node()
An expression prefixed with a period and forward slash (./) explicitly uses the current context as the context Example: ./author – all <author> elements within the current context .//title – All <title> elements one or more levels deep in the current context node. book[. = ‘Disney’] means that for every book that is found in the current context, test whether its value is Disney. |
| .. | The parent of the current node. This is an abbreviation for parent::node()
../para Selects the <para> element that is the parent of the context node. |
| @ | Prefix for an attribute name.
Attributes cannot contain child elements, so syntax errors occur when path operators are applied to attributes. In addition, you cannot apply an index to attributes because, by definition, no order is defined for attributes. Example: @style – The style attribute of the current element context. price/@exchange – The exchange attribute of <price> elements within the current context. book/@style – The style attribute of all <book> elements. price/@exchange/total – Invalid because an attribute cannot have any children.//input[@id=’firstName’] OR //*[@id=’ firstName ‘] //input[@name= firstName ‘] OR //*[@name=’ firstName ‘] //form[@id=’loginForm’]/input[1] OR //*[@id=’loginForm’]/input[1] //form[@name=’loginForm’]/input[1] OR //*[@name=’loginForm’]/input[1] |
| * | Wildcard; This is an abbreviation for child::*
An element can be referenced without using its name by substituting the wildcard (*) collection. The * collection refers to all elements that are children of the current context, regardless of the tag name. Example: /* – An expression that uses a forward slash followed by an asterisk (/*) uses the root element as the context. */* – All grandchildren elements of the current context. //* – Selects all elements in the document author/* – All children element of <author> elements. author/*/last-name – All <last–name> elements that are grandchildren of <author> elements. /bookstore/* – Selects all the child nodes of the bookstore element bookstore/*/title – All <title> elements that are grandchildren of <bookstore> elements. |
| @* | Attribute wildcard; All attributes of current context node. This is an abbreviation for attribute::*
Example: //title[@*] – Selects all title elements which have at least one attribute of any kind |
| : | Namespace separator; separates the namespace prefix from the element or attribute name.
Example: my:book – The <book> element from the my namespace. my:* – All elements from the my namespace. |
| | | This operator allows to select several paths
Example: //book/title | //book/price – Selects all the title AND price elements of all book elements //title | //price – Selects all the title AND price elements in the document /bookstore/book/title | //price – Selects all the title elements of the book element of the bookstore element AND all the price elements in the document |
| ( ) | Groups operations to explicitly establish precedence.
Example: (//comment())[3] – Selects the third comment from the set of all comments relative to the parent. |
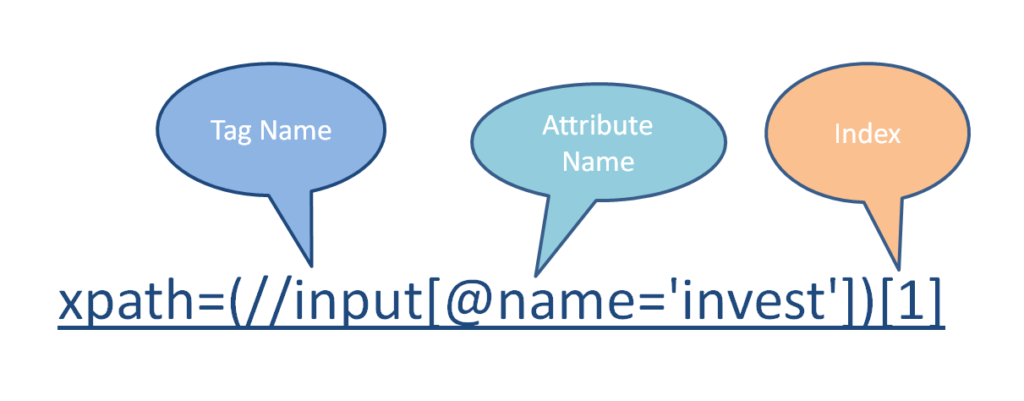
| [ ] | Subscript operator; used for indexing within a collection.
Example: //*[@name=’email’][1] //form[@id=’customerSearch’]/table/tbody/tr/td[2]/input[1] //input[@name=’employee’])[1] //input[@name=’email’][@style=’background-color: transparent;’] |
Logical & Comparison Operators
| Operator | Description |
| and | Logical-and operator requires both conditions to be true.
//input[@name=’name2′ and @value=’yes’] //div[@class=’bubble-title’ and contains(text(), ‘Cover’) |
| or | Logical-or operator requires either of the condition or both conditions to be true.
//*[@id=’email’ or @name=’email’], here first it will check for the id and then it will check for the second. |
| Not( ) | Negation is used to reverse the logical state of its operand.
//div[@class=’detail’][1]//text()[not(ancestor::h5)] |
| = | Equals
/bookstore/book[price=35.00] |
| != | Not Equals
/bookstore/book[price!=35.00] |
| < | Less Than
/bookstore/book[price<35.00] |
| <= | Less than or Equal
/bookstore/book[price<=35.00] |
| > | Greater than
/bookstore/book[price>35.00] |
| >= | Greater than or equal
/bookstore/book[price>=35.00] |
Precedence Order
Precedence order (from highest precedence to lowest) is defined as indicated in the following table.
| Precedence | Symbol | Purpose |
| 1 | ( ) | Grouping |
| 2 | [ ] | Filters |
| 3 | / // | Path operations |
The group operator, (), is applicable only at the top-level path expression. For example, (//author/degree | //author/name) is a valid grouping operation, but //author/(degree | name) is not.
The filter pattern operators ([ ]) have a higher precedence than the path operators (/ and //). For example, the expression //comment()[3] selects all comments with an index equal to 3 relative to the comment’s parent anywhere in the document. This differs from the expression (//comment())[3], which selects the third comment from the set of all comments relative to the parent. The first expression can return more than one comment, while the latter can return only one comment.
Note that indexes are relative to the set being filtered. Consider following example:
<x>
<y/>
<y/>
</x>
<x>
<y/>
<y/>
</x>
The following table shows how to select specific <x> and <y> elements.
| Expression | Meaning |
| x/y[1] | The first <y> inside each <x>. |
| (x/y)[1] | The first <y> from the entire set of <y> elements within <x> elements. |
| x[1]/y[1] | The first <y> inside the first <x>. |
Predicates
It allows applying a filter pattern. Predicates are used to find a specific node or a node that contains a specific value. Predicates are always embedded in square brackets.
Few examples of predicates are given below:
| Path Expression | Result |
| /bookstore/book[1] | Selects the first book element that is the child of the bookstore element. |
| /bookstore/book[last()] | Selects the last book element inside each bookstore element |
| /bookstore/book[last()-1] | Selects the second last element that is the child of the bookstore element |
| (book/author)[last()] | The last <author> element from the entire set of <author> elements inside <book> elements. |
| /bookstore/book[position()<3] | Selects the first two book elements that are children of the bookstore element |
| /bookstore/book[price>35.00] | Selects all the book elements of the bookstore element that have a price element with a value greater than 35.00 |
| The following example /bookstore/book/price[text()] | Selects the text from all the price nodes
|
XPath Axes
XPath Axes helps to locate elements based on element’s relationship with other elements in a document. While using XPath Axes, the syntax for a location step is:
axisname::nodetest[predicate]
XPath has a total of 13 different axes:
| Axis Name | Description |
| self | Selects current node |
| ancestor | Selects ancestors of the context node, that is, the parent of the context node, parent’s parent etc.
ancestor::book Selects all book ancestors of the current node //div[@class=’detail_block’][1]//text()[not(ancestor::h5)] Selects text from div 1 that is not under h5 (ancestor is not h5) |
| ancestor-or-self | Selects the context node and its ancestors
ancestor-or-self::book Selects all book ancestors of the current node – and the current as well if it is a book node |
| attribute | Selects all the attribute of the context node
attribute::lang Selects the lang attribute of the current node attribute::* Selects all attributes of the current node |
| Child | Selects all children of the context node. The child axis is the default axis, so it need not be explicitly expressed. For this axis, the collection of child nodes is indexed in forward document order.
//child::table Selects all table nodes that are children of the current node. child::* Selects all element children of the current node child::text() Selects all text node children of the current node child::node() Selects all children of the current node child::*/child::price Selects all price grandchildren of the current node x/child::y[1] This expression is equivalent to x/y[1]. Both expressions mean “for each <x> element, select the first child element named <y>. |
| descendant | Children of the context node, the children of those children, etc.
descendant::book Selects all book descendants of the current node |
| descendant-or-self | Selects context node and its descendants |
| following | Selects everything in the document after the closing tag of the context node.
The below syntax selects the immediate node following the specified node input[@id=’email’] //input[@id=’email’]/following::* |
| following-sibling | The following-sibling axis selects those nodes that are siblings of the context node (i.e. the context node and its sibling nodes share a parent node) and which occur later in document order than the context node.
//select[@id=’month’]/following-sibling::* |
| namespace | Selects all the namespace nodes, if any, of the context node |
| Parent | Selects Parent of the context node if it has one. The parent node may be either the root node or an element node. The root node has no parent; therefore, when the context node is the root node, the parent axis is empty. For all other element nodes the parent axis contains one node.parent::node()The below example will selects the parent node of the input tag of Id=’email’.//input[@id=’email’]/parent::*The above can also be re-written as//input[@id=’email’]/.. |
| preceding | The preceding axis contains all nodes in the same document as the context node that are before the context node in document order.
//input[@id=’pass’]/preceding::tr |
| preceding-sibling | The preceding-sibling axis selects those nodes which are siblings of the context node (that is, the context node and its sibling nodes share a parent node) and which occur earlier in document order than the context node.
//select[@id=’day’]/preceding-sibling::select/ //select[@id=’day’]/preceding-sibling::* |
Note: The child axis is the default axis, so it need not be explicitly expressed. For this axis, the collection of child nodes is indexed in forward document order.
x/y[1]
This expression is equivalent to this one:
x/child::y[1]
Both expressions mean “for each <x> element, select the first child element named <y>.”
For other axes, such as ancestor::, use the axis name explicitly in your XPath expression. For this axis, the collection of ancestors is indexed in reverse document order:
The following example uses the same syntax:
x/ancestor::y[1]
This example translates to “for each <x> element, select the first ancestor element (in reverse-document order) named <y>”. The syntax is the same, but the order is reversed.
Functions
Some useful functions that can help you while writing XPath location:
| position() | Returns the index position of the node that is currently being processed
//book[position()<=3] |
| last() | Returns the number of items in the processed node list
//book[last()] |
| matches(string,pattern) | Returns true if the string argument matches the pattern, otherwise, it returns false
//input[matches(@id,’reportcombo’) |
| starts-with(string1,string2) | Returns true if string1 starts with string2, otherwise it returns false
//input[starts-with(@id,’reportcombo’) |
| ends-with(string1,string2) | Returns true if string1 ends with string2, otherwise it returns false
//a[ends-with(.,’Reset’)]/@href |
| contains(string1,string2) | Returns true if string1 contains string2, otherwise it returns false
//a[contains(.,’Reset’)]/@href |
| normalize-space(string) | The normalize-space function strips leading and trailing white-space from a string, replaces sequences of whitespace characters by a single space, and returns the resulting string
//div[./div/div[normalize-space(.)=’More Actions…’]] //td[contains(normalize-space(@class), ‘actualcell sajcell-row-lines saj-special x-grid-row-collapsed’)] //label[//text()[normalize-space() = ‘some label’]] |
Working with Text
When writing XPath for elements that involves some text, consider below scenarios:
1. ‘Exactly’ Matches
‘Exactly’ will try to find the exact match.
If a button displays exact text as ‘Search All’, we can use below XPath:
//button[.=’Search All’]
2. ‘Contains’
Contains looks for multiple matches.
Examples:
XPath: //span[contains(text(), ‘Assign Rate’)]
XPath: //div[contains(text(),’Sign up’)] OR alternative XPath: //div[contains(text(),’Sign’)]
XPath: //div[contains(@class,’dojoxGridView’)\\input
For a link with text ‘link=Forgot your password?’,
XPath: //a[contains(text(),’Forgot’)].
This also can be written as //a[contains(.,’Forgot’)]. Here we have replaced ‘text()’ with ‘dot’.
OR alternative XPath: //a[.=’Forgot your password?’]
To verify this:
<div class="Captain">
Model saved
</div>
You can use XPath: //div[contains(@class, ‘Captain’) and text()=’Model saved’]
3. XPath determination through String Formatting
There are few code examples using Java + Selenium, explaining XPath determination for an element that can have different text in different situations. In such a case, text can be stored in a variable as shown below:
private final String myId = “//*[contains(@id,’%s’)]”;
String text = ‘Some text goes here’;
driver.findElement(By.xpath(String.format(myId, text)));
Another Example:
texttolookfor = “Summary”
targetElement= driver.findElement(By.xpath ("//tr[contains(., '%s')]/td[@class='button-cell']" % texttolookfor)
If no string formatting is used for above scenario, XPath can be written as below:
buttonelement= webDriver.find_element_by_xpath("//tr[contains(., 'Wednesday')]/td[@class='button-cell']")
Please comment with your real name using good manners.